RPC-概述
本文最后更新于:1 年前
[TOC]
RPC(Remote Procedure Call)即远程过程调用。
为什么要 RPC ?因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
RPC 能帮助我们做什么呢? 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。
RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。
RPC VS HTTP
无论是微服务还是分布式服务(都是 SOA,都是面向服务编程),都面临着服务间的远程调用。那么服务间的远程调用方式有哪些呢?
常见的远程调用方式有以下几种:
RPC:Remote Produce Call 远程过程调用。自定义数据格式,基于原生 TCP 通信,速度快,效率高。早期的 webservice,现在热门的 dubbo,都是 RPC 的典型
Http:http 其实是一种网络传输协议,基于 TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用 Http 协议。也可以用来进行远程服务调用。缺点是消息封装臃肿。
现在热门的 Rest 风格,就可以通过 http 协议来实现。
相同点:底层通讯都是基于网络编程,都可以实现远程调用,都可以实现服务调用服务。
不同点:
当使用 RPC 框架实现服务间调用的时候,要求服务提供方和服务消费方 都必须使用统一的 RPC 框架,跨操作系统在同一编程语言内使用
优势:调用快、处理快
http:
当使用 http 进行服务间调用的时候,无需关注服务提供方使用的编程语言,也无需关注服务消费方使用的编程语言,服务提供方只需要提供 restful 风格的接口,服务消费方,按照 restful 的原则,请求服务,即可跨系统跨编程语言的远程调用框架
优势:通用性强
restful
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。
在 RPC 样式的架构中,关注点在于方法,而在 REST 样式的架构中,关注点在于资源 —— 将使用标准方法检索并操作信息片段(使用表示的形式)。资源表示形式在表示形式中使用超链接互联。
RESTful 架构是对 MVC 架构改进后所形成的一种架构,通过使用事先定义好的接口与不同的服务联系起来。在 RESTful 架构中,浏览器使用 POST,DELETE,PUT 和 GET 四种请求方式分别对指定的 URL 资源进行增删改查操作。因此,RESTful 是通过 URI 实现对资源的管理及访问,具有扩展性强、结构清晰的特点。
RESTful 架构将服务器分成前端服务器和后端服务器两部分,前端服务器为用户提供无模型的视图;后端服务器为前端服务器提供接口。浏览器向前端服务器请求视图,通过视图中包含的 AJAX 函数发起接口请求获取模型。
项目开发引入 RESTful 架构,利于团队并行开发。在 RESTful 架构中,将多数 HTTP 请求转移到前端服务器上,降低服务器的负荷,使视图获取后端模型失败也能呈现。但 RESTful 架构却不适用于所有的项目,当项目比较小时无需使用 RESTful 架构,项目变得更加复杂。
(1)每一个 URI 代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个 HTTP 动词,对服务器端资源进行操作,实现”表现层状态转化”。

RPC 中网络传输协议
基于 TCP 协议的 RPC 调用
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法。
将结果返回给服务的调用方,整个基于 TCP 协议的 RPC 调用大致如此。
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的 Java 对象。
基于 HTTP 协议的 RPC 调用
该方法更像是访问网页一样,只是它的返回结果更加单一简单。
其大致流程为:由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式。
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,返回 JOSN 或者 XML 的数据结果。
由于前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样。
两种方式对比
基于 TCP 的协议实现的 RPC 调用,由于 TCP 协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,减少网络开销,提高性能,实现更大的吞吐量和并发数。
但是需要更多关注底层复杂的细节,实现的代价更高。同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据。
而 JSON 和 XML 作为通用的格式标准(使用 HTTP 协议也需要序列化和反序列化,不过这不是该协议下关心的内容,成熟的 Web 程序已经做好了序列化内容),开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。
但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,使用 HTTP 协议传输所占用的字节数会比使用 TCP 协议传输所占用的字节数更高。
因此在同等网络下,通过 HTTP 协议传输相同内容,效率会比基于 TCP 协议的数据效率要低,信息传输所占用的时间也会更长,当然压缩数据,能够缩小这一差距。
简单对比 RPC 和 Restful API
RESTful API 架构
REST 的几个特点为:资源、统一接口、URI 和无状态。
①资源
所谓”资源”,就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,就是一个具体的实在。
②统一接口
RESTful 架构风格规定,数据的元操作,即 CRUD(Create,Read,Update 和 Delete,即数据的增删查改)操作,分别对应于 HTTP 方法:GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT 用来更新资源,DELETE 用来删除资源,这样就统一了数据操作的接口,仅通过 HTTP 方法,就可以完成对数据的所有增删查改工作。
③URL
可以用一个 URI(统一资源定位符)指向资源,即每个 URI 都对应一个特定的资源。
要获取这个资源,访问它的 URI 就可以,因此 URI 就成了每一个资源的地址或识别符。
④无状态
所谓无状态的,即所有的资源,都可以通过 URI 定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变。有状态和无状态的区别,举个简单的例子说明一下。
如查询员工的工资,如果查询工资是需要登录系统,进入查询工资的页面,执行相关操作后,获取工资的多少,则这种情况是有状态的。
因为查询工资的每一步操作都依赖于前一步操作,只要前置操作不成功,后续操作就无法执行。
如果输入一个 URI 即可得到指定员工的工资,则这种情况是无状态的,因为获取工资不依赖于其他资源或状态。
且这种情况下,员工工资是一个资源,由一个 URI 与之对应,可以通过 HTTP 中的 GET 方法得到资源,这是典型的 RESTful 风格。
RPC 和 Restful API 对比
面对对象不同:
RPC 更侧重于动作。
REST 的主体是资源。
RESTful 是面向资源的设计架构,但在系统中有很多对象不能抽象成资源,比如登录,修改密码等而 RPC 可以通过动作去操作资源。所以在操作的全面性上 RPC 大于 RESTful。
传输效率:
RPC 效率更高。RPC,使用自定义的 TCP 协议,可以让请求报文体积更小,或者使用 HTTP2 协议,也可以很好的减少报文的体积,提高传输效率。
复杂度:
RPC 实现复杂,流程繁琐。
REST 调用及测试都很方便。
RPC 实现需要实现编码,序列化,网络传输等。而 RESTful 不要关注这些,RESTful 实现更简单。
灵活性:
HTTP 相对更规范,更标准,更通用,无论哪种语言都支持 HTTP 协议。
RPC 可以实现跨语言调用,但整体灵活性不如 RESTful。
总结
RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等。
RPC 使用场景(大型的网站,内部子系统较多、接口非常多的情况下适合使用 RPC):
长链接。不必每次通信都要像 HTTP 一样去 3 次握手,减少了网络开销。
注册发布机制。RPC 框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
安全性,没有暴露资源操作。
微服务支持。就是最近流行的服务化架构、服务化治理,RPC 框架是一个强力的支撑。
原理
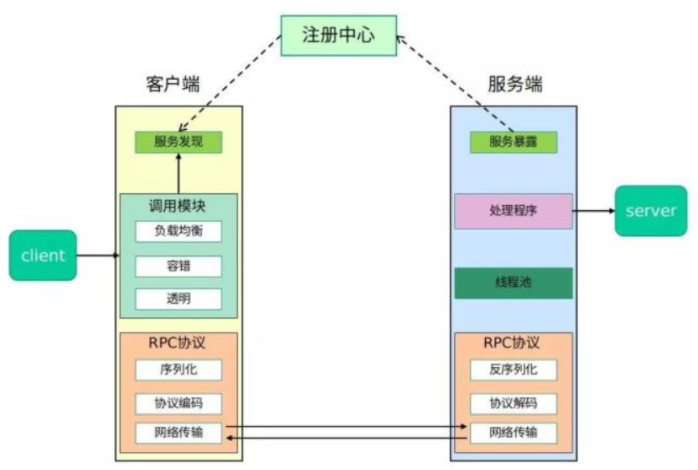
client 调用远程方法-> request 序列化 -> 协议编码 -> 网络传输-> 服务端 -> 解码->反序列化 request -> 调用本地方法得到 response -> 序列化 ->编码->……..
常见的 RPC 框架
Dubbo
是一款高性能、轻量级的开源 Java RPC 框架,它提供了三大核心能力:
面向接口的远程方法调用
智能容错和负载均衡
服务自动注册和发现。
简单来说 Dubbo 是一个分布式服务框架,致力于提供高性能和透明化的 RPC 远程服务调用方案,以及 SOA 服务治理方案。
Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
Motan
motan 是 2016 年新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑着千亿次调用。
很多人喜欢拿 motan 和 Dubbo 作比较,毕竟都是国内大公司开源的。笔者在查阅了很多资料,以及简单查看了其源码之后发现:motan 更像是一个精简版的 dubbo,可能是借鉴了 Dubbo 的思想,motan 的设计更加精简,功能更加纯粹。
不过,我不推荐你在实际项目中使用 motan。如果你要是公司实际使用的话,还是推荐 Dubbo ,其社区活跃度以及生态都要好很多。
gRPC
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计,基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
通过 ProtoBuf 定义接口和数据类型还挺繁琐的,虽然 gRPC 确实很多亮点的地方,但是我还是选择 Dubbo。
Thrift
Apache Thrift 是 Facebook 开源的跨语言的 RPC 通信框架,目前已经捐献给 Apache 基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于 thrift 研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
Thrift 支持多种不同的编程语言,包括 C++、Java、Python、PHP、Ruby 等(相比于 gRPC 支持的语言更多 )。
总结
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是因为它们只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑。
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的。最重要的是其在国内有很多成功的案例比如当当网、滴滴等等。下图展示了 Dubbo 的生态系统。
但是,Dubbo 和 Motan 主要是给 Java 语言使用。虽然,Dubbo 和 Motan 目前也能兼容部分语言,但是不太推荐。如果需要跨语言调用的话,可以考虑一下 Thrift 和 gRPC。
自己实现 RPC 框架的思路
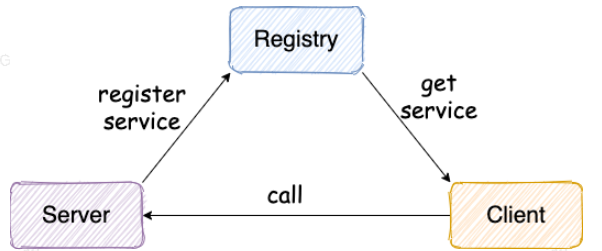
注册中心
zookeeper 作为注册中心的问题?
在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性
注册中心需要的是 AP,而 Zookeeper 是 CP
CAP :一致性、可用性、分区容忍性
一致性:是指在同一时刻,分布式系统中的所有数据备份为相同值
可用性:指集群中的某一个节点故障宕机后,集群还能响应客户端请求。
分区容忍性:当分布式系统中因为一些原因导致无法通信而分成多个分区,系统还能正常对外服务。
在 CAP 模型中,zookeeper 是 CP,意味着面对网络分区时,为了保持一致性,他是不可用的。
因为 zookeeper 是一个分布式协调系统,如果使用最终一致性(AP)的话,将是一个糟糕的设计,他的核心算法是 ZAb,所有设计都是为了一致性。
对于协调系统,这是非常正确的,但是对于服务发现,可用性是第一位的,例如发生了短暂的网络分区时,即使拿到的信息是有瑕疵的、旧的,也好过完全不可用。
注册中心本质上的功能就是一个查询函数:
ServiceList = F(service-name)
以 service-name 为查询参数,得到对应的可用的服务端点列表 endpoints(ip:port)。
1,我们假设不同的客户端得到的服务列表数据是不一致的,看看有什么后果。
现在有 2 个服务调用者 service1 和 service2,从注册中心获取 serviceB 的服务列表,但取得的数据不一致。
s1 = { ip1,ip2 … ip9 }
s2 = { ip2,ip3 … ip10 }
这个不一致带来的影响是什么?
就是 serviceB 各个实例的流量不均衡。
这个不均衡有什么严重影响吗?并没有,完全可以接受,而且,又不会一直这样。
所以,注册中心使用最终一致性模型(AP)完全可以的。
2,现在我们看一下 CP 带来的不可用的影响。
3 个机房部署 5 个 ZK 节点。
现在机房 3 出现网络分区了,形成了孤岛。
发生网络分区时,各个区都会开始选举 leader,那么节点数少的那个分区将会停止运行,也就是 ZK5 不可用了。
这时,serviceA 就访问不了机房 1 和机房 2 的 serviceB 了,而且连自己所在机房的 serviceB 也访问不了了。
不能访问其他机房还可以理解,不能访问自己机房的服务就理解不了了,本机房内部的网络好好的,不能因为你注册中心有问题就不能访问了吧。
因为注册中心为了保障数据一致性而放弃了可用性,导致同机房服务之间无法调用,这个是接受不了的。
所以,注册中心的可用性比数据强一致性更加重要,所以注册中心应该是偏向 AP,而不是 CP。
zookeeper 的性能不适合注册中心
在大规模服务集群场景中,zookeeper 的性能也是瓶颈。
zookeeper 所有的写操作都是 leader 处理的,在大规模服务注册写请求时,压力巨大,而且 leader 是单点,无法水平扩展。
还有所有服务于 zookeeper 的长连接也是很重的负担。
zookeeper 对每一个写请求,都会写一个事务日志,同时会定期将内存数据镜像 dump 到磁盘,保持数据一致性和持久性。这个动作会降低性能,而且对于注册中心来讲,是不需要的。
小结
从 CP 模型上来讲,zookeeper 并不适合注册中心高可用的需要。
从性能上来讲,zookeeper 也无法满足注册中心大规模且频繁注册写的场景。
zookeeper 的特长是做分布式协调服务,例如 kafka、hbase、flink、hadoop 等大项目都在用 zookeeper。
redis 注册中心
redis 作为 dubbo 的注册中心,实现的功能跟 zk 相同,但是内部的实现机制大相径庭,因为 zk 有临时节点,服务端在 zk 中创建临时节点会一直保持连接,如果服务器出现崩溃,自动断连,而 redis 则要靠主服务器 进行定时轮询
服务发现
1 | |
服务注册
1 | |
推荐使用 Zookeeper 作为注册中心。当然了,你也可以使用 Nacos ,甚至是 Redis。
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。并且,ZooKeeper 将数据保存在内存中,性能是非常棒的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。
当然了,如果你想通过文件来存储服务地址的话也是没问题的,不过性能会比较差。
注册中心负责服务地址的注册与查找,相当于目录服务。 服务端启动的时候将服务名称及其对应的地址(ip+port)注册到注册中心,服务消费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消费端就可以通过网络请求服务端了。
常用命令
查看常用命令(help 命令)
通过 help 命令查看 ZooKeeper 常用命令
创建节点(create 命令)
通过 create 命令在根目录创建了 node1 节点,与它关联的字符串是”node1”
create /node1 “node1”
更新节点数据内容(set 命令)
set /node1 “set node1”
获取节点的数据(get 命令)
get 命令可以获取指定节点的数据内容和节点的状态
查看某个目录下的子节点(ls 命令)
通过 ls 命令查看根目录下的节点
ls /
通过 ls 命令查看 node1 目录下的节点
ls /node1
查看节点状态(stat 命令)
通过 stat 命令查看节点状态
stat /node1
比如 cversion、aclVersion、numChildren 等等
查看节点信息和状态(ls2 命令)
ls2 命令更像是 ls 命令和 stat 命令的结合。 ls2 命令返回的信息包括 2 部分:
子节点列表
当前节点的 stat 信息。
删除节点(delete 命令)
这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
连接 zookeeper
通过 CuratorFrameworkFactory 创建 CuratorFramework 对象,然后再调用 CuratorFramework 对象的 start() 方法即可
1 | |
baseSleepTimeMs:重试之间等待的初始时间
maxRetries :最大重试次数
connectString :要连接的服务器列表
retryPolicy :重试策略
zookeeper 常见概念
ZooKeeper 典型应用场景
分布式锁 : 通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。
命名服务 :可以通过 ZooKeeper 的顺序节点生成全局唯一 ID
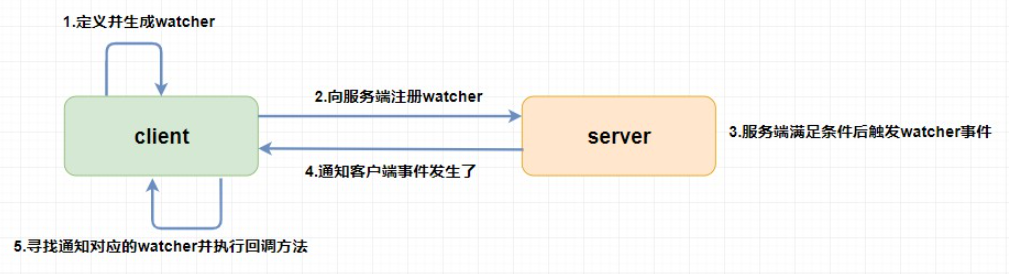
数据发布/订阅 :通过 Watcher 机制 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
Data model(数据模型)
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的上限是每个结点的数据大小最大是 1M。
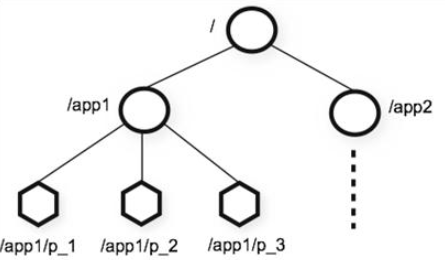
znode 4 种类型
持久(PERSISTENT)节点 :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
临时(EPHEMERAL)节点 :临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失 。并且,临时节点只能做叶子节点 ,不能创建子节点。
持久顺序(PERSISTENT_SEQUENTIAL)节点 :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 /node1/app0000000001 、/node1/app0000000002 。
临时顺序(EPHEMERAL_SEQUENTIAL)节点 :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
每个 znode 由 2 部分组成:
stat :状态信息
data : 节点存放的数据的具体内容
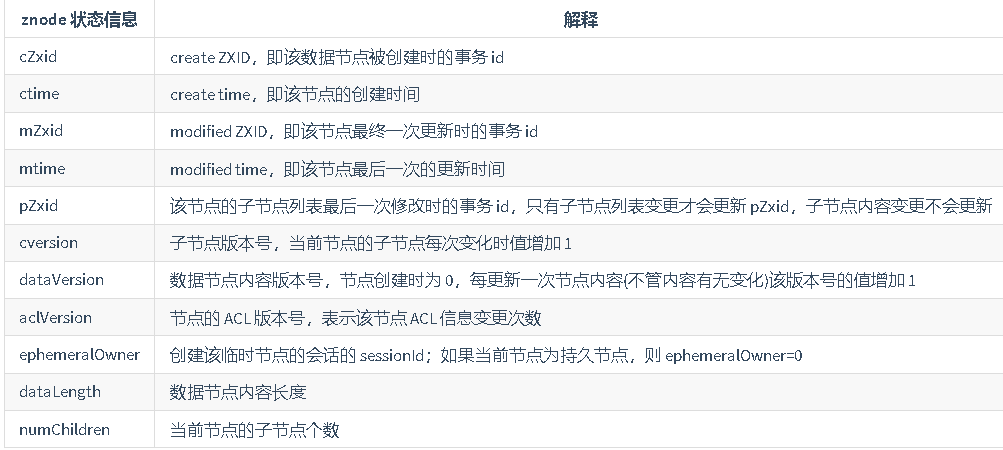
ACL(权限控制)
ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。
对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
CREATE : 能创建子节点
READ :能获取节点数据和列出其子节点
WRITE : 能设置/更新节点数据
DELETE : 能删除子节点
ADMIN : 能设置节点 ACL 的权限
Watcher(事件监听器)
Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ZooKeeper 集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。
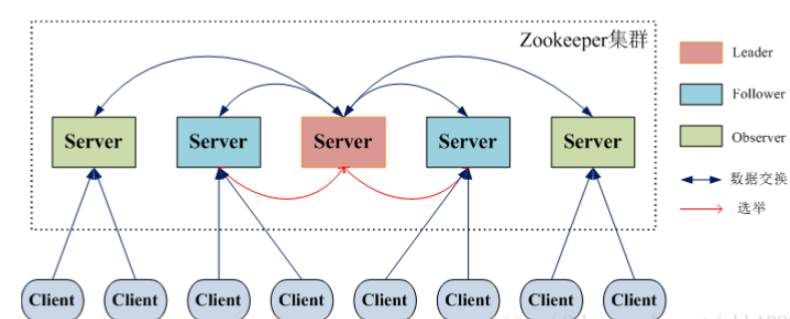
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
Discovery(发现阶段) :在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
Synchronization(同步阶段) :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后 准 leader 才会成为真正的 leader。
Broadcast(广播阶段) :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群为啥最好奇数台?
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。 假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
何为集群脑裂?
对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
ZAB 协议包括两种基本的模式,分别是
崩溃恢复 :当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
消息广播 :当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
CAP
分布式系统的最大难点,就是各个节点的状态如何保持一致。CAP 理论是在设计分布式系统的过程中,处理数据一致性问题时必须考虑的理论。
CAP 即:
Consistency(一致性)
Availability(可用性)
Partition tolerance(分区容忍性)
①一致性:对于客户端的每次读操作,要么读到的是最新的数据,要么读取失败。换句话说,一致性是站在分布式系统的角度,对访问本系统的客户端的一种承诺:要么我给您返回一个错误,要么我给你返回绝对一致的最新数据,不难看出,其强调的是数据正确。
②可用性:任何客户端的请求都能得到响应数据,不会出现响应错误。换句话说,可用性是站在分布式系统的角度,对访问本系统的客户的另一种承诺:我一定会给您返回数据,不会给你返回错误,但不保证数据最新,强调的是不出错。
③分区容忍性:由于分布式系统通过网络进行通信,网络是不可靠的。当任意数量的消息丢失或延迟到达时,系统仍会继续提供服务,不会挂掉。换句话说,分区容忍性是站在分布式系统的角度,对访问本系统的客户端的再一种承诺:我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉。
假设 N1 和 N2 之间通信的时候网络突然出现故障,有用户向 N1 发送数据更新请求,那 N1 中的数据 DB0 将被更新为 DB1,由于网络是断开的,N2 中的数据库仍旧是 DB0;
如果这个时候,有用户向 N2 发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据 DB1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据 DB0 给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作完成之后,再给用户响应最新的数据 DB1。
raft 协议
有三个节点:a,b,c。客户端对这个由 3 个节点组成的数据库集群进行操作时的值一致性如何保证,就是分布式一致性问题。Raft 就是一种实现了分布式一致性的协议(还有其他一些一致性算法,例如:ZAB、PAXOS 等)
分布式锁
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用并发处理相关的功能进行互斥控制。但是,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的应用并不能提供分布式锁的能力。为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问。
基于数据库
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
问题:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的 insert 操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决:
数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
非阻塞的?搞一个 while 循环,直到 insert 成功再返回成功。
非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于数据库排它锁
在查询语句后面增加 for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name 添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。
当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过**connection.commit()**操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
阻塞锁? for update 语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
问题?
MySql 会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。
还有一个问题,就是我们要使用排他锁来进行分布式锁的 lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆。
基于 redis
可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,redis 的 setnx 方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
(1)SETNX
SETNX key val:当且仅当 key 不存在时,set 一个 key 为 val 的字符串,返回 1;若 key 存在,则什么都不做,返回 0。
(2)expire
expire key timeout:为 key 设置一个超时时间,单位为 second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除 key
实现思想:
(1)获取锁的时候,使用 setnx 加锁,并使用 expire 命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value 值为一个随机生成的 UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过 UUID 判断是不是该锁,若是该锁,则执行 delete 进行锁释放。
设置的失效时间太短,方法没等执行完,锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间。
基于 zookeeper
基于 zookeeper 临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在 zookeeper 上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
锁无法释放?使用 Zookeeper 可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在 ZK 中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session 连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
非阻塞锁?使用 Zookeeper 可以实现阻塞的锁,客户端可以通过在 ZK 中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper 会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
不可重入?使用 Zookeeper 也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
单点问题?使用 Zookeeper 可以有效的解决单点问题,ZK 是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
其实,使用 Zookeeper 也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端和 ZK 集群的 session 连接断了,那么 ZK 以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。
这个问题不常见是因为 zk 有重试机制,一旦 zk 集群检测不到客户端的心跳,就会重试,Curator 客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。
从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
网络传输
网络传输实体类
1 | |
1 | |
netty 网络客户传输
NettyClient.java
doConnect() :用于连接服务端(目标方法所在的服务器)并返回对应的 Channel。当我们知道了服务端的地址之后,我们就可以通过 NettyClient 成功连接服务端了。(有了 Channel 之后就能发送数据到服务端了)
sendRpcRequest() : 用于传输 rpc 请求(RpcRequest) 到服务端。
UnprocessedRequests.java
用于存放未被服务端处理的请求(建议限制 map 容器大小,避免未处理请求过多 OOM)。
NettyClientHandler
自定义客户端 ChannelHandler 用于处理服务器发送的数据。
从代码中,可以看出当 rpc 请求被成功处理(客户端收到服务端的执行结果)之后,我们调用了 unprocessedRequests.complete(rpcResponse) 方法,这样的话,你只需要通过下面的方式就能成功接收到客户端返回的结果
1 | |
ChannelProvider.java
用于存放 Channel(Channel 用于在服务端和客户端之间传输数据)。
NettyRpcServer.java
Netty 服务端。并监听客户端的连接。
NettyServerHandler.java
自定义服务端 ChannelHandler 用于处理客户端发送的数据。
当客端发的 rpc 请求(RpcRequest) 来了之后,服务端就会处理 rpc 请求(RpcRequest) ,处理完之后就把得到 rpc 相应(RpcResponse)传输给客户端。
既然我们要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的参数等数据到服务提供端。
网络传输具体实现你可以使用 Socket ( Java 中最原始、最基础的网络通信方式。但是,Socket 是阻塞 IO、性能低并且功能单一)。
你也可以使用同步非阻塞的 I/O 模型 NIO ,但是用它来进行网络编程真的太麻烦了。不过没关系,你可以使用基于 NIO 的网络编程框架 Netty ,它将是你最好的选择。
Netty 是一个基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。
它极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。
支持多种协议如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
socket
服务器端:
创建 ServerSocket 对象并且绑定地址(ip)和端口号(port):
1 | |
通过 accept()方法监听客户端请求
连接建立后,通过输入流读取客户端发送的请求信息
1 | |
通过输出流向客户端发送响应信息
1 | |
关闭相关资源
管理多个客户端
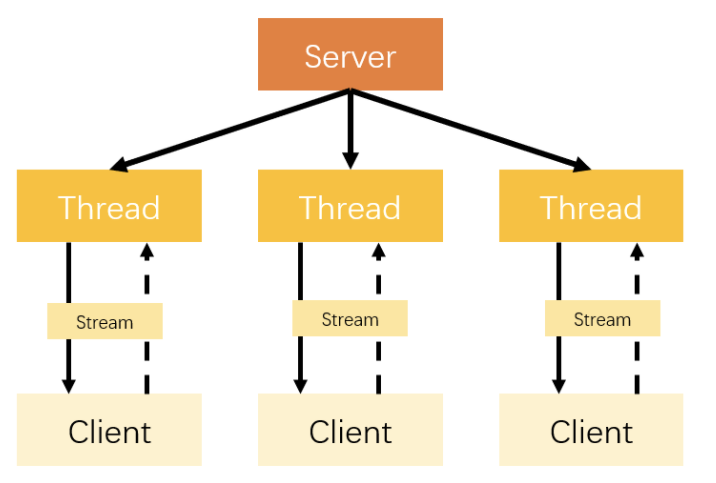
比较简单并且实际的改进方法就是使用线程池。线程池还可以让线程的创建和回收成本相对较低,并且我们可以指定线程池的可创建线程的最大数量,这样就不会导致线程创建过多,机器资源被不合理消耗。
客户端:
创建 Socket 对象并且连接指定的服务器的地址(ip)和端口号(port):
1 | |
连接建立后,通过输出流向服务器端发送请求信息
1 | |
通过输入流获取服务器响应的信息
1 | |
关闭相关资源
Netty
Netty 是一个基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。
它极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。
支持多种协议如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
Netty 成功地找到了一种在不妥协可维护性和性能的情况下实现易于开发,性能,稳定性和灵活性的方法。
这个应该是老铁们最关心的一个问题了,凭借自己的了解,简单说一下,理论上 NIO 可以做的事情 ,使用 Netty 都可以做并且更好。Netty 主要用来做网络通信 :
应用
作为 RPC 框架的网络通信工具
实现一个自己的 HTTP 服务器
实现一个即时通讯系统
消息推送系统
……
Dubbo、RocketMQ、Elasticsearch、gRPC 等等都用到了 Netty。
客户端
客户端中主要有一个用于向服务端发送消息的 **sendMessage()**方法,通过这个方法你可以将消息也就是 RpcRequest 对象发送到服务端,并且你可以同步获取到服务端返回的结果也就是 RpcResponse 对象。
sendMessage()方法分析:
首先初始化了一个 Bootstrap
1 | |
通过 Bootstrap 对象连接服务端
1 | |
通过 Channel 向服务端发送消息 RpcRequest
1 | |
发送成功后,阻塞等待 ,直到 Channel 关闭
1 | |
拿到服务端返回的结果 RpcResponse
1 | |
(NettyClientHandler用于读取服务端发送过来的 RpcResponse 消息对象,并将 RpcResponse 消息对象保存到 AttributeMap 上。
AttributeMap 可以看作是一个 Channel 的共享数据源。这样的话,我们就能通过 channel 和 key 将数据读取出来。
AttributeMap ,AttributeMap 是一个接口,但是类似于 Map 数据结构 。
Channel 实现了 AttributeMap 接口,这样也就表明它存在了 AttributeMap 相关的属性。 每个 Channel 上的 AttributeMap 属于共享数据。AttributeMap 的结构,和 Map 很像,我们可以把 key 看作是 AttributeKey,value 看作是 Attribute,我们可以根据 AttributeKey 找到对应的 Attribute。)
1 | |
服务端
1 | |
编码器
NettyKryoEncoder 是我们自定义的编码器。它负责处理”出站”消息,将消息格式转换为字节数组然后写入到字节数据的容器 ByteBuf 对象中。
4B magic code(魔法数)
1B version(版本)
4B full length(消息长度)
1B messageType(消息类型)
1B compress(压缩类型)
1B codec(序列化类型)
4B requestId(请求的 Id)
1 | |
解码器
1 | |
序列化和反序列化
要在网络传输数据就要涉及到序列化。为什么需要序列化和反序列化呢?
因为网络传输的数据必须是二进制的。因此,我们的 Java 对象没办法直接在网络中传输。为了能够让 Java 对象在网络中传输我们需要将其序列化为二进制的数据。我们最终需要的还是目标 Java 对象,因此我们还要将二进制的数据“解析”为目标 Java 对象,也就是对二进制数据再进行一次反序列化。
另外,不仅网络传输的时候需要用到序列化和反序列化,将对象存储到文件、数据库等场景都需要用到序列化和反序列化。
JDK 自带的序列化,只需实现 java.io.Serializable 接口即可,不过这种方式不推荐,因为不支持跨语言调用并且性能比较差。
现在比较常用序列化的有 hessian、kyro、protostuff ……
属于哪一层?
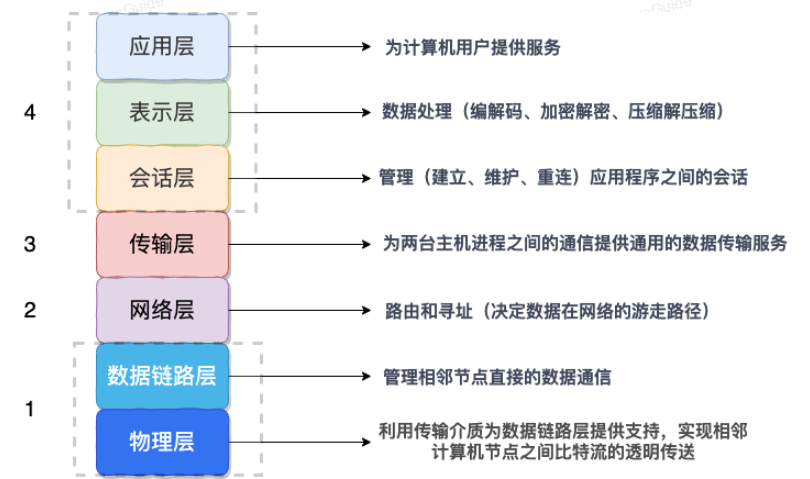
OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。
因为,OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序列化协议属于 TCP/IP 协议应用层的一部分。
常见序列化协议对比
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且部分版本有安全漏洞。比较常用的序列化协议有 hessian、kyro、protostuff。
下面提到的都是基于二进制的序列化协议,像 JSON 和 XML这种属于文本类序列化方式。虽然 JSON 和 XML 可读性比较好,但是性能较差。
JDK 自带的序列化方式
JDK 自带的序列化,只需实现 java.io.Serializable接口即可。
序列化号 serialVersionUID 属于版本控制的作用。序列化的时候 serialVersionUID 也会被写入二级制序列,当反序列化时会检查 serialVersionUID 是否和当前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的序列化号。
kyro
Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。
另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。
1 | |
hession
hessian 是一个轻量级的,自定义描述的二进制 RPC 协议。hessian 是一个比较老的序列化实现了,并且同样也是跨语言的。
Protobuf
Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不然灵活,但是,另一方面导致 protobuf 没有序列化漏洞的风险。
动态代理
我们知道代理模式就是: 我们给某一个对象提供一个代理对象,并由代理对象来代替真实对象做一些事情。你可以把代理对象理解为一个幕后的工具人。 举个例子:我们真实对象调用方法的时候,我们可以通过代理对象去做一些事情比如安全校验、日志打印等等。但是,这个过程是完全对真实对象屏蔽的。
RPC 的主要目的就是让我们调用远程方法像调用本地方法一样简单,我们不需要关心远程方法调用的细节比如网络传输。
当你调用远程方法的时候,实际会通过代理对象来传输网络请求,不然的话,怎么可能直接就调用到远程方法。
JDK 动态代理
在 Java 动态代理机制中 InvocationHandler 接口和 Proxy 类是核心。
Proxy 类中使用频率最高的方法是:newProxyInstance() ,这个方法主要用来生成一个代理对象。
plain public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
这个方法一共有 3 个参数:
loader :类加载器,用于加载代理对象。
interfaces : 被代理类实现的一些接口;
h : 实现了 InvocationHandler 接口的对象;
要实现动态代理的话,还必须需要实现 InvocationHandler 来自定义处理逻辑。 当我们的动态代理对象调用一个方法时候,这个方法的调用就会被转发到实现 InvocationHandler 接口类的 invoke 方法来调用。
invoke() 方法有下面三个参数:
proxy :动态生成的代理类
method : 与代理类对象调用的方法相对应
args : 当前 method 方法的参数
也就是说:你通过 Proxy 类的 newProxyInstance() 创建的代理对象在调用方法的时候,实际会调用到实现 InvocationHandler 接口的类的 invoke()方法。 你可以在 invoke() 方法中自定义处理逻辑,比如在方法执行前后做什么事情。
步骤:
定义一个接口及其实现类;
自定义 InvocationHandler 并重写 invoke 方法,在 invoke 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
通过 Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法创建代理对象;
1 | |
CGLIB 动态代理
JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。
为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。
CGLIB(Code Generation Library)是一个基于 ASM 的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了 CGLIB, 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
在 CGLIB 动态代理机制中 MethodInterceptor 接口和 Enhancer 类是核心。
你需要自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法。
CGLIB 动态代理类使用步骤
定义一个类;
自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法,和 JDK 动态代理中的 invoke 方法类似;
通过 Enhancer 类的 create()创建代理类;
比较
JDK 动态代理和 CGLIB 动态代理对比
JDK 动态代理只能只能代理实现了接口的类,而 CGLIB 可以代理未实现任何接口的类。 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
静态代理和动态代理的对比
灵活性 :动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改。
JVM 层面 :静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
代码
RpcClientProxy.java
当我们去调用一个远程的方法的时候,实际上是通过代理对象调用的。
网络传输细节都被封装在了 invoke() 方法中。
1 | |
负载均衡
系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题。
代码
我们定义了两个接口 ServiceDiscovery.java 和 ServiceRegistry.java,这两个接口分别定义了服务发现和服务注册行为。
1 | |
当我们的服务被注册进 zookeeper 的时候,我们将完整的服务名称 rpcServiceName (class name+group+version)作为根节点 ,子节点是对应的服务地址(ip+端口号)。
class name : 服务接口名也就是类名比如:github.javaguide.HelloService。
version :(服务版本)主要是为后续不兼容升级提供可能
group :主要用于处理一个接口有多个类实现的情况。
一个根节点(rpcServiceName)可能会对应多个服务地址(相同服务被部署多份的情况)。
1 | |
具体算法
1 | |
随机
轮询
一致性哈希
简单的路由算法可以使用余数哈希算法:HashCode = key % number of server。由于 HashCode 具有随机性,因此使用余数哈希路由算法可保证缓存数据在整个 Memcached 服务器集群中比较均衡地分布。
假设由于业务发展,网站需要将 3 台缓存服务器扩容至 4 台。更改服务器列表,仍旧使用余数 Hash,很容易就可以计算出,3 台服务器扩容至 4 台服务器,大约有 75%(3/4)被缓存了的数据不能正确命中,随着服务器集群规模的增大,这个比例线性上升。当 100 台服务器的集群中加入一台新服务器,不能命中的概率是 99%(N/(N+1))。
假设扩容前有 N 台服务器,扩容一台服务器
也就是说每(N+1)*N 个数里面有 N 个 key 经过余数 Hash 映射后是一样的,所以命中率为 1/(N+1),所以未命中率为(N/(N+1))
当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这些数据访问的压力就落到了数据库的身上,这将大大超过数据库的负载能力,严重的可能会导致数据库宕机。
一致性 Hash 算法通过一个叫作一致性 Hash 环的数据结构实现 key 到缓存服务器的 Hash 映射。
具体算法过程为:先构造一个长度为0~2^32的整数环(这个环被称作一致性 Hash 环),根据节点名称(通常是 IP)的 Hash 值(其分布范围同样为0~x^32)将缓存服务器节点放置在这个 Hash 环上。然后根据需要缓存的数据的 key 值计算得到其 Hash 值(其分布范围也同样为0~x^32),然后在 Hash 环上顺时针查找距离这个 key 的 Hash 值最近的缓存服务器节点,完成 key 到服务器的 Hash 映射查找。
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(NODE3)的 Hash 值放入一致性 Hash 环中,由于 key 是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一小段。
上图中,加入新节点NODE3后,原来的 key 大部分还能继续计算到原来的节点,只有key3、key0从原来的NODE1重新计算到NODE3。这样就能保证大部分被缓存的数据还可以继续命中。3 台服务器扩容至 4 台服务器,可以继续命中原有缓存数据的概率是 75%,远高于余数 Hash 的 25%,而且随着集群规模越大,继续命中原有缓存数据的概率也逐渐增大,100 台服务器扩容增加 1 台服务器,继续命中的概率是 99%。虽然仍有小部分数据缓存在服务器中不能被读到,但是这个比例足够小,通过访问数据库获取也不会对数据库造成致命的负载压力。
虚拟节点
新加入的节点NODE3只影响了原来的节点NODE1,也就是说一部分一部分原来需要访问NODE1的缓存数据现在需要访问NODE3。但是原来的节点NODE0和NODE2不受影响,这就意味着NODE0和NODE2缓存数据量和负载压力是NODE1与NODE3的两倍。如果 4 台机器的性能是一样的,那么这种结果显然不是我们需要的。
怎么办?计算机领域有句话:计算机的任何问题都可以通过增加一个虚拟层来解决。计算机硬件、计算机网络、计算机软件都莫不如此。计算机网络的 7 层协议,每一层都可以看作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java 虚拟机可以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
解决上述一致性 Hash 算法带来的负载不均衡问题,也可以通过使用虚拟层的手段:将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的 Hash 值放置在 Hash 环上,key 在环上先找到虚拟服务器节点,再得到物理服务器的信息。
这样新加入物理服务器节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点又对应不同的物理节点。
最终的结果是:新加入一台缓存服务器,将会较为均匀地影响原来集群中已经存在的所有服务器,也就是说分摊原有缓存服务器集群中所有服务器的一小部分负载,其总的影响范围和上面讨论过的相同。
新加入节点NODE3对应的一组虚拟节点为V30,V31,V32,加入到一致性 Hash 环上后,影响V01,V12,V22三个虚拟节点,而这三个虚拟节点分别对应NODE0,NODE1,NODE2三个物理节点。最终 Memcached 集群中加入一个节点,但是同时影响到集群中已存在的三个物理节点,在理想情况下,每个物理节点受影响的数据量(还在缓存中,但是不能被访问到数据)为其节点缓存数据量的 1/4(X/(N+X),N 为原有物理节点数,X 为新加入物理节点数),也就是集群中已经被缓存的数据有 75%可以被继续命中,和未使用虚拟节点的一致性 Hash 算法结果相同。显然每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致(这就是一致性 Hash 这个名称的由来)。
版本一
考虑最简单的 RPC 功能。
客户端调用服务端方法,服务端返回。
1,有一个 User 对象,是客户端与服务端都已知的
2,定义客户端需要调用,服务端需要提供的服务接口 UserService
3,服务端需要实现 UserService 接口的功能 UserServiceImpl
4,客户端建立 Socket 连接,传输 Id 给服务端,得到返回的 User 对象
5,服务端以 BIO 的方式监听 Socket,如有数据,调用对应服务的实现类执行任务,将结果返回给客户端
问题
只能调用服务端唯一的方法
返回值也只只支持一种
版本 2
定义了一个通用的 Request 的对象(消息格式)
(在上个版本中,Request 仅仅只发送了一个 id 参数过去,这显然是不合理的,
因为服务端不会只有一个服务一个方法,因此只传递参数不会知道调用那个方法。
因此一个 RPC 请求中,client 发送应该是需要调用的 Service 接口名,方法名,参数,参数类型
这样服务端就能根据这些信息根据反射调用相应的方法。
还是使用 java 自带的序列化方式。)
定义了一个通用的 Response 的对象(消息格式)
(上个版本中 response 传输的是 User 对象,显然在一个应用中我们不可能只传输一种类型的数据
由此我们将传输对象抽象成为 Object
。Rpc 需要经过网络传输,有可能失败,引入状态码和状态信息表示服务调用成功还是失败)
通过 jdk 动态代理封装传输细节, 每一次代理对象调用方法,会经过 invoke 方法增强(反射获取 request 对象,socket 发送至客户端,得到返回的 rpcresponce)
客户端反射得到结果
// 读取客户端传过来的 request
RPCRequest request = (RPCRequest) ois.readObject();
// 反射调用对应方法
Method method = userService.getClass().getMethod(request.getMethodName(), request.getParamsTypes());
Object invoke = method.invoke(userService, request.getParams());
// 封装,写入 response 对象
oos.writeObject(RPCResponse.success(invoke));
问题
服务端直接绑定的是 UserService 服务,如果还有其它服务接口暴露呢(多个服务的注册)
服务端以 BIO 的方式性能太低
解决
用一个 Map 来保存,<interfaceName, xxxServiceImpl>
此时来了一个 request,就能从 map 中取出对应的服务
Object service = map.get(request.getInterfaceName())
服务端用线程池
threadPool = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors(),
1000, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
版本 3
netty 改善
客户端
//超时设定:5 秒没连接就断开
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000)
.handler(new ChannelInitializer
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
//5 秒没有数据发送,就发送心跳包。
p.addLast(new IdleStateHandler(0, 5, 0, TimeUnit.SECONDS));
p.addLast(new RpcMessageEncoder());//编码
p.addLast(new RpcMessageDecoder());//解码
p.addLast(new NettyRpcClientHandler());
}
});
4B magic code(魔法数) 1B version(版本) 4B full length(消息长度) 1B messageType(消息类型-request,reaponse,心跳)
1B compress(压缩类型) 1B codec(序列化类型) 4B requestId(请求的 Id)
服务端
// TCP 默认开启了 Nagle 算法,该算法的作用是尽可能的发送大数据快,减少网络传输。TCP_NODELAY 参数的作用就是控制是否启用 Nagle 算法。
.childOption(ChannelOption.TCP_NODELAY, true)
// 是否开启 TCP 底层心跳机制
.childOption(ChannelOption.SO_KEEPALIVE, true)
//表示系统用于临时存放已完成三次握手的请求的队列的最大长度,如果连接建立频繁,服务器处理创建新连接较慢,可以适当调大这个参数
.option(ChannelOption.SO_BACKLOG, 128)
.handler(new LoggingHandler(LogLevel.INFO))
// 当客户端第一次进行请求的时候才会进行初始化
.childHandler(new ChannelInitializer
@Override
protected void initChannel(SocketChannel ch) {
// 30 秒之内没有收到客户端请求的话就关闭连接
ChannelPipeline p = ch.pipeline();
p.addLast(new IdleStateHandler(30, 0, 0, TimeUnit.SECONDS));
p.addLast(new RpcMessageEncoder());
p.addLast(new RpcMessageDecoder());
p.addLast(serviceHandlerGroup, new NettyRpcServerHandler());
问题:服务端与客户端通信的 host 与 port 预先就必须知道的,每一个客户端都必须知道对应服务的 ip 与端口号, 并且如果服务挂了或者换地址了,就很麻烦。扩展性也不强。
版本 4
zookeeper 注册中心
public void registerService(String rpcServiceName, InetSocketAddress inetSocketAddress) {
String servicePath = CuratorUtils.ZK_REGISTER_ROOT_PATH + “/“ + rpcServiceName + inetSocketAddress.toString();
CuratorFramework zkClient = CuratorUtils.getZkClient();
CuratorUtils.createPersistentNode(zkClient, servicePath);
}
public InetSocketAddress lookupService(RpcRequest rpcRequest) {
String rpcServiceName = rpcRequest.getRpcServiceName();
CuratorFramework zkClient = CuratorUtils.getZkClient();
List
if (serviceUrlList == null || serviceUrlList.size() == 0) {
throw new RpcException(RpcErrorMessageEnum.SERVICE_CAN_NOT_BE_FOUND, rpcServiceName);
}
// load balancing
String targetServiceUrl = loadBalance.selectServiceAddress(serviceUrlList, rpcRequest);
plain String[] socketAddressArray = targetServiceUrl.split(“:”);
String host = socketAddressArray[0];
int port = Integer.parseInt(socketAddressArray[1]);
return new InetSocketAddress(host, port);
}
简单的负载均衡
随机
轮询
一致性哈希
容错
在 RPC 中可选的网络传输方式有多种,可以选择 TCP 协议、UDP 协议、HTTP 协议。
基于 TCP 协议的 RPC 调用
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法。
将结果返回给服务的调用方,整个基于 TCP 协议的 RPC 调用大致如此。
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的 Java 对象。
基于 HTTP 协议的 RPC 调用
该方法更像是访问网页一样,只是它的返回结果更加单一简单。
其大致流程为:由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式。
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,返回 JOSN 或者 XML 的数据结果。
由于目前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样。
两种方式对比
基于 TCP 的协议实现的 RPC 调用,由于 TCP 协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,减少网络开销,提高性能,实现更大的吞吐量和并发数。
但是需要更多关注底层复杂的细节,实现的代价更高。同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据。
而 JSON 和 XML 作为通用的格式标准(使用 HTTP 协议也需要序列化和反序列化,不过这不是该协议下关心的内容,成熟的 Web 程序已经做好了序列化内容),开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。
但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,使用 HTTP 协议传输所占用的字节数会比使用 TCP 协议传输所占用的字节数更高。
因此在同等网络下,通过 HTTP 协议传输相同内容,效率会比基于 TCP 协议的数据效率要低,信息传输所占用的时间也会更长,当然压缩数据,能够缩小这一差距。
简单对比 RPC 和 Restful API
RESTful API 架构
REST 的几个特点为:资源、统一接口、URI 和无状态。
①资源
所谓”资源”,就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,就是一个具体的实在。
②统一接口
RESTful 架构风格规定,数据的元操作,即 CRUD(Create,Read,Update 和 Delete,即数据的增删查改)操作,分别对应于 HTTP 方法:GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT 用来更新资源,DELETE 用来删除资源,这样就统一了数据操作的接口,仅通过 HTTP 方法,就可以完成对数据的所有增删查改工作。
③URL
可以用一个 URI(统一资源定位符)指向资源,即每个 URI 都对应一个特定的资源。
要获取这个资源,访问它的 URI 就可以,因此 URI 就成了每一个资源的地址或识别符。
④无状态
所谓无状态的,即所有的资源,都可以通过 URI 定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变。有状态和无状态的区别,举个简单的例子说明一下。
如查询员工的工资,如果查询工资是需要登录系统,进入查询工资的页面,执行相关操作后,获取工资的多少,则这种情况是有状态的。
因为查询工资的每一步操作都依赖于前一步操作,只要前置操作不成功,后续操作就无法执行。
如果输入一个 URI 即可得到指定员工的工资,则这种情况是无状态的,因为获取工资不依赖于其他资源或状态。
且这种情况下,员工工资是一个资源,由一个 URI 与之对应,可以通过 HTTP 中的 GET 方法得到资源,这是典型的 RESTful 风格。
RPC 和 Restful API 对比
面对对象不同:
RPC 更侧重于动作。
REST 的主体是资源。
RESTful 是面向资源的设计架构,但在系统中有很多对象不能抽象成资源,比如登录,修改密码等而 RPC 可以通过动作去操作资源。所以在操作的全面性上 RPC 大于 RESTful。
传输效率:
RPC 效率更高。RPC,使用自定义的 TCP 协议,可以让请求报文体积更小,或者使用 HTTP2 协议,也可以很好的减少报文的体积,提高传输效率。
复杂度:
RPC 实现复杂,流程繁琐。
REST 调用及测试都很方便。
RPC 实现需要实现编码,序列化,网络传输等。而 RESTful 不要关注这些,RESTful 实现更简单。
灵活性:
HTTP 相对更规范,更标准,更通用,无论哪种语言都支持 HTTP 协议。
RPC 可以实现跨语言调用,但整体灵活性不如 RESTful。
总结
RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等。
RPC 使用场景(大型的网站,内部子系统较多、接口非常多的情况下适合使用 RPC):
长链接。不必每次通信都要像 HTTP 一样去 3 次握手,减少了网络开销。
注册发布机制。RPC 框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
安全性,没有暴露资源操作。
微服务支持。就是最近流行的服务化架构、服务化治理,RPC 框架是一个强力的支撑。