消息队列
本文最后更新于:1 年前
[TOC]
消息队列是一种中间件。
中间件就是一类为应用软件服务的软件,应用软件是为用户服务的,用户不会接触或者使用到中间件。
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
作用
通过异步处理提高系统性能(减少响应所需时间)
项目:
元数据变更
记录变更
强制解除(先返回解除中,异步消费消息同步元数据,再发消息返回成功)
削峰/限流
降低系统耦合性。
不同微服务都来消费元数据,数据变更消息,workflow、数据集等。
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。 从上图可以看到消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计。
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
分布式事务
问题
- 系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
- 系统复杂性提高: 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
选型
持久化和可靠性
- RabbitMQ:RabbitMQ采用消息持久化机制,消息被持久化到磁盘上,保证消息的可靠性。支持多种消息确认机制和事务,可以保证消息的可靠传递。
- RocketMQ:RocketMQ具有强大的持久化和可靠性特性,支持同步刷盘和异步复制机制,能够提供高可靠性的消息传递保证。
- Kafka:Kafka以持久化的方式存储消息,消息被写入磁盘上的日志文件。通过分区和复制机制,提供了高可靠性和持久化存储的能力。
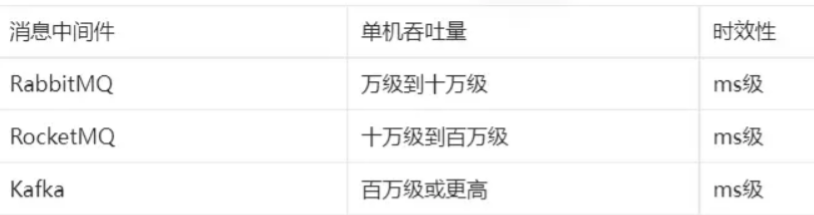
吞吐量
- RabbitMQ:RabbitMQ的吞吐量通常较低,适合中小规模的应用场景。RabbitMQ适用于中小规模的应用场景,通常能够处理万级到十万级的消息量级。它主要侧重于消息的可靠性传递和消息的持久化,对于高吞吐量的需求可能需要进行优化和调整。
- RocketMQ:RocketMQ具有较高的吞吐量,可以达到百万级消息的处理能力。它在分布式事务和大规模消息传递场景下表现出色。
- Kafka:Kafka是以高吞吐量而著称的消息队列系统,能够处理百万级甚至更高的消息量级。Kafka适用于大规模数据处理、实时流处理和日志处理等高吞吐量场景。
响应时间
社区及生态
rabbitmq<rocketmq<kafka
- RabbitMQ:RabbitMQ拥有丰富的插件和工具生态系统,具有广泛的开发者社区支持。
- RocketMQ:RocketMQ在国内得到广泛应用,具有丰富的阿里巴巴生态系统和社区支持。
- Kafka:Kafka拥有活跃的开源社区和广泛的生态系统,被许多大型公司广泛采用。
设计理念
- RabbitMQ:RabbitMQ是一个基于AMQP(高级消息队列协议)的开源消息中间件,强调易用性和灵活性,支持多种消息模式和可靠的消息传递。
- RocketMQ:RocketMQ是阿里巴巴开源的分布式消息中间件,最初是为了满足阿里巴巴内部的海量数据处理需求而设计的,具有高吞吐量和低延迟的特点。在2016年阿里巴巴将RocketMQ捐赠给了Apache软件基金会。
- Kafka:Kafka是由LinkedIn开发的分布式流处理平台,主要用于高吞吐量的实时数据流处理,以持久化的方式存储和处理数据。在2011年Kafka成为Apache开源项目。
数据模型
- RabbitMQ:RabbitMQ采用队列(Queue)模型,消息被发送到队列中,消费者从队列中接收消息并进行处理。
- RocketMQ:RocketMQ采用主题(Topic)和标签(Tag)的模型,消息被发布到主题上,消费者可以根据主题和标签进行订阅和过滤消息。
- Kafka:Kafka采用发布-订阅的模型,消息被发布到主题上,多个消费者可以订阅同一个主题并独立消费消息。
消息模式
主流的消息中间件的传输模型主要为点对点模型和发布订阅模型。具体来说:
- RabbitMQ:
- 发布-订阅模式:RabbitMQ支持发布-订阅模式,其中生产者将消息发布到交换机(Exchange),然后交换机将消息传递给多个绑定(Binding)到它的队列。消费者可以独立地从队列中接收消息。
- 点对点模式:RabbitMQ也支持点对点模式,其中生产者将消息发送到指定的队列,然后消费者从该队列中接收消息。每条消息只能被一个消费者接收和处理。
2.RocketMQ:
- 发布-订阅模式:RocketMQ支持发布-订阅模式,其中生产者将消息发送到指定的主题(Topic),然后消费者订阅感兴趣的主题。RocketMQ的订阅模式支持多种订阅方式,如广播模式和集群模式,可以实现消息的多播或负载均衡消费。
- 队列模式:RocketMQ还支持队列模式,其中生产者将消息发送到指定的队列,然后消费者从指定的队列中接收消息。多个消费者可以并行地从同一个队列消费消息。
3.Kafka:
- 发布-订阅模式:Kafka采用发布-订阅模式,其中生产者将消息发布到指定的主题(Topic),然后消费者订阅感兴趣的主题。Kafka的订阅模式支持多个消费者组,每个消费者组都可以独立地消费消息,实现了高吞吐量和水平扩展。
- 分区模式:Kafka通过分区将主题划分为多个分区,每个分区在物理上对应一个独立的日志文件。生产者将消息发送到指定分区,消费者可以按照分区进行并行消费。这种分区模式使得Kafka能够实现水平扩展和高吞吐量
RocketMQ
架构
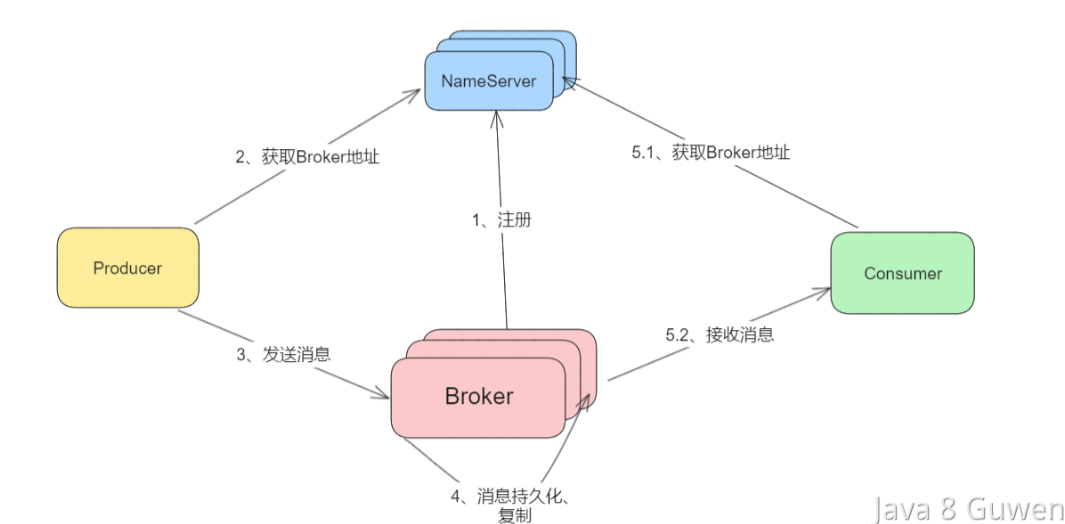
RocketMQ主要由Producer、Broker和Consumer三部分组成。
- Producer:消息生产者,负责将消息发送到Broker。
- Broker:消息中转服务器,负责存储和转发消息。RocketMQ支持多个Broker构成集群,每个Broker都拥有独立的存储空间和消息队列。
- Consumer:消息消费者,负责从Broker消费消息。
NameServer:名称服务,负责维护Broker的元数据信息,包括Broker地址、Topic和Queue等信息。Producer和Consumer在启动时需要连接到NameServer获取Broker的地址信息,心跳包检测 boker 状态。
Topic:消息主题,是消息的逻辑分类单位。Producer将消息发送到特定的Topic中,Consumer从指定的Topic中消费消息。
Message Queue:消息队列,是Topic的物理实现。一个Topic可以有多个Queue,每个Queue都是独立的存储单元。Producer发送的消息会被存储到对应的Queue中,Consumer从指定的Queue中消费消息。
事务消息
发消息前有事务,事务和发消息要保持一致性,不推荐将发消息耦合性在事务中,可用事务消息。
在发送事务消息时,首先向RocketMQ Broker发送一条“half消息”(即半消息),半消息将被存储在Broker端的事务消息日志中,但是这个消息还不能被消费者消费。
接下来,在半消息发送成功后,应用程序通过执行本地事务来确定是否要提交该事务消息。
如果本地事务执行成功,就会通知RocketMQ Broker提交该事务消息,使得该消息可以被消费者消费;否则,就会通知RocketMQ Broker回滚该事务消息,该消息将被删除,从而保证消息不会被消费者消费。
顺序消费
和Kafka只支持同一个Partition内消息的顺序性一样,RocketMQ中也提供了基于队列(分区)的顺序消费。即同一个队列内的消息可以做到有序,但是不同队列内的消息是无序的
总结下来就是三次加锁,先锁定Broker上的MessageQueue,确保消息只会投递到唯一的消费者,对本地的MessageQueue加锁,确保只有一个线程能处理这个消息队列。对存储消息的ProcessQueue加锁,确保在重平衡的过程中不会出现消息的重复消费。
性能较差,非必要不用。
保证消息不丢失
broker 集群部署,一主多从
在消费者端,需要确保在消息拉取并消费成功之后再给Broker返回ACK,就可以保证消息不丢失了,如果这个过程中Broker一直没收到ACK,那么就可以重试。
所以,在消费者的代码中,一定要在业务逻辑的最后一步return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; 当然,也可以先把数据保存在数据库中,就返回,然后自己再慢慢处理。
但是,需要注意的是RocketMQ和Kafka一样,只能最大限度的保证消息不丢失,但是没办法做到100%保证不丢失。
业务:
16次重试,都消费失败就丢失。kafka 不支持重试
也会持久化消息。
延时消息
kafka 不支持
RocketMQ的延迟消息并不是支持任意时长的延迟的,它只支持(5.0之前):1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h这几个时长。
另外,RocketMQ 5.0中新增了基于时间轮实现的定时消息。
前面提到的延迟消息,并使用Timer定时器来实现延迟投递。但是,由于Timer定时器有一定的缺陷,比如在定时器中有大量任务时,会导致定时器的性能下降,从而影响消息投递。
因此,在RocketMQ 5.0中,采用了一种新的实现方式:基于时间轮的定时消息。时间轮是一种高效的定时器算法,能够处理大量的定时任务,并且能够在O(1)时间内找到下一个即将要执行的任务,因此能够提高消息的投递性能。
并且,基于时间轮的定时消息能够支持更高的消息精度,可以实现秒级、毫秒级甚至更小时间粒度的定时消息。
具体实现方式如下:
-
RocketMQ在Broker端使用一个时间轮来管理定时消息,将消息按照过期时间放置在不同的槽位中,这样可以大幅减少定时器任务的数量。
- 时间轮的每个槽位对应一个时间间隔,比如1秒、5秒、10秒等,每次时间轮的滴答,槽位向前移动一个时间间隔。
- 当Broker接收到定时消息时,根据消息的过期时间计算出需要投递的槽位,并将消息放置到对应的槽位中。
- 当时间轮的滴答到达消息的过期时间时,时间轮会将该槽位中的所有消息投递给消费者。
消费堆积
生产
消费
增加消费者数量:消息堆积了,消费不过来了,那就把消费者的数量增加一下,让更多的实例来消费这些消息。
提升消费者消费速度:消费者消费的慢可能是消息堆积的主要原因,想办法提升消费速度,比如引入线程池、本地消息存储后即返回成功后续再慢慢消费等。
降低生产者的生产速度:如果生产者可控的话,可以让生产者生成消息的速度慢一点。
清理过期消息:有一些过期消息、或者一直无法成功的消息,在业务做评估之后,如果无影响或者影响不大,其实是可以清理的。
调整 RocketMQ 的配置参数:RocketMQ 提供了很多可配置的参数,例如消息消费模式、消息拉取间隔时间等,可以根据实际情况来调整这些参数,从而优化消息消费的效率。
增加 Topic 队列数:如果一个 Topic 的队列数比较少,那么就容易出现消息堆积的情况。可以通过增加队列数来提高消息的处理并发度,从而减少消息堆积。
消费模式
RocketMQ 支持两种消息模式:广播消费( Broadcasting )和集群消费( Clustering )。
广播消费:当使用广播消费模式时,RocketMQ 会将每条消息推送给集群内所有的消费者,保证消息至少被每个消费者消费一次。
集群消费:当使用集群消费模式时,RocketMQ 认为任意一条消息只需要被集群内的任意一个消费者处理即可。
集群模式下,每一条消息都只会被分发到一台机器上处理。但是不保证每一次失败重投的消息路由到同一台机器上。一般来说,用集群消费的更多一些。
推拉
MQ的消费模式可以大致分为两种,一种是推Push,一种是拉Pull
Push是服务端主动推送消息给客户端,Pull是客户端需要主动到服务端轮询获取数据。
他们各自有各自的优缺点,推优点是及时性较好,但如果客户端没有做好流控,一旦服务端推送大量消息到客户端时,就会导致客户端消息堆积甚至崩溃。
拉优点是客户端可以依据自己的消费能力进行消费,但是频繁拉取会给服务端造成压力,并且可能会导致消息消费不及时。
RocketMQ既提供了Push模式也提供了Pull模式,开发者可以自行选择。
一般来说,拉的模式可以削峰。