Mysql-架构与存储引擎
本文最后更新于:1 年前
[TOC]
问题
char varchar
char和varchar都是用于在数据库中存储字符串的数据类型。它们之间的主要区别在于存储空间的使用方式:
char是一种定长的数据类型,它的长度固定且在存储时会自动在结尾添加空格来将字符串填满指定的长度。char的长度范围是0-255,
varchar是一种可变长度的数据类型,它只会存储实际的字符串内容,不会填充空格。因此,在存储短字符串时,varchar可以节省空间。varchar的长度范围是0-65535(MySQL 5.0.3之后的版本)。
varchar 的优点是变长的字符串类型,兼容性更好;但是同时也会带来一些问题,如使用varchar可能会产生内存碎片、varchar 会额外需要1到2个字节存储长度信息、以及update语句可能会导致页分裂等。
char的优点是定长的字符串类型,减少内存碎片,并且无需额外的磁盘空间去存储长度信息。但是他的缺点是会删除列末尾的空格信息
存储身份证号(固定长度)、存储订单号(固定长度)、存储国家编码(固定长度),这些都适合用char。
范式
所谓数据库范式,其实就是数据库的设计上的一些规范;这些规范可以让数据库的设计更加简洁、清晰;同时也会更加好的可以保证一致性。
三个常用的范式:
第一范式(1NF)是说,数据库表中的属性的原子性的,要求属性具有原子性,不可再被拆分;
比如地址如果都细化拆分成省、市、区、街道、小区等等多个字段这就是符合第一范式的, 如果地址就是一个字段,那就不符合了。
第二范式(2NF)是说,数据库表中的每个实例或记录必须可以被唯一地区分,说白了就是要有主键,其他的字段都依赖于主键。
第三范式(3NF)是说,任何非主属性不依赖于其它非主属性,也就是说,非主键外的所有字段必须互不依赖
如果我们在做表结构设计的时候,完全遵守数据库三范式,确实可以避免一些写时异常,提升一些写入性能,但是同时也会丢失一些读取性能。
因为在遵守范式的数据库设计中,表中不能有任何冗余字段,这就使得查询的时候就会经常有多表关联查询,这无疑是比较耗时的。
于是就有了反范式化。所谓反范式化,是一种针对遵从设计范式的数据库的性能优化策略。
也就是说,反范式化不等于非范式化,反范式化一定发生在满足范式设计的基础之上。前者相当于先遵守所有规则,再进行局部调整。
比如我们可以在表中增加一些冗余字段,方便我们进行数据查询,而不再需要经常做多表join,但同时,这也会带来一个问题,那就是这些冗余字段之间的一致性如何保证,这个问题本来在遵守范式的设计中是不会有的,一旦做了反范式,那就需要开发者自行解决了。
反范式其实本质上是软件开发中一个比较典型的方案,那就是”用空间换时间”,通过做一些数据冗余,来提升查询速度。
在互联网业务中,比较典型的就是数据量大,并发高,并且通常查询的频率要远高于写入的频率,所以适当的做一些反范式,通过做一些字段的冗余,可以提升查询性能,降低响应时长,从而提升并发度。
架构
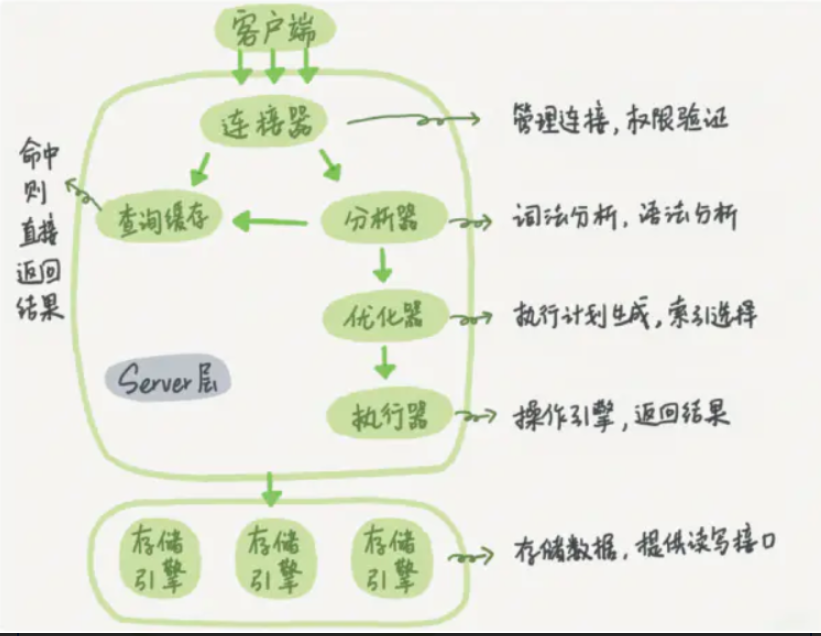
Mysql 逻辑架构图主要分三层
(1)第一层负责连接处理,授权认证,安全等等
(2)第二层负责编译并优化 SQL
(3)第三层是存储引擎。、
sql 执行2
select * from users where age=’18’ and name=’Hollis’;
①使用连接器,通过客户端/服务器通信协议与 MySQL 建立连接。并查询是否有权限
②Mysql8.0之前检查是否开启缓存,开启了 Query Cache 且命中完全相同的 SQL 语句,则将查询结果直接返回给客户端;
③由解析器(分析器)进行语法分析和语义分析,并生成解析树。如查询是select、表名users、条件是age=’18’ and name=’Hollis’,预处理器则会根据 MySQL 规则进一步检查解析树是否合法。比如检查要查询的数据表或数据列是否存在等。
④由优化器生成执行计划。根据索引看看是否可以优化
⑤执行器来执行SQL语句,这里具体的执行会操作MySQL的存储引擎来执行 SQL 语句,根据存储引擎类型,得到查询结果。若开启了 Query Cache,则缓存,否则直接返回。
sql 语句执行流程
查询语句的执行流程如下:权限校验(如果命中缓存)—>查询缓存—>分析器—>优化器—>权限校验—>执行器—>引擎
更新语句执行流程如下:分析器—->权限校验—->执行器—>引擎—redo log(prepare 状态)—>binlog—>redo log(commit 状态)
MySQL 自带的日志模块是 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志),我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
1
update tb_student A set A.age='19' where A.name=' 张三 ';然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
更新完成。
为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
先写 redo log 直接提交,然后写 binlog,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
先写 binlog,然后写 redo log,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。
那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢? 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
判断 redo log 是否完整,如果判断是完整的,就立即提交。
如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
这样就解决了数据一致性的问题。
Server 层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
存储引擎: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。
存储引擎对比
innodb vs myisam
是否支持行级锁
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
是否支持事务
MyISAM 不提供事务支持。
InnoDB 提供事务支持,具有提交(commit)和回滚(rollback)事务的能力。
是否支持外键
MyISAM 不支持,而 InnoDB 支持。
是否支持数据库异常崩溃后的安全恢复
MyISAM 不支持,而 InnoDB 支持。
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 redo log 。
MySQL InnoDB 引擎使用 redo log(重做日志) 保证事务的持久性,使用 undo log(回滚日志) 来保证事务的原子性。
MySQL InnoDB 引擎通过 锁机制、MVCC 等手段来保证事务的隔离性( 默认支持的隔离级别是 REPEATABLE-READ )。
保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
是否支持 MVCC
MyISAM 不支持,而 InnoDB 支持。