Redis-线程模型,事务
本文最后更新于:1 年前
[TOC]
redis 为什么快
- 基于内存:Redis 是一种基于内存的数据库,数据存储在内存中,数据的读写速度非常快,因为内存访问速度比硬盘访问速度快得多。
- 单线程模型:Redis 使用单线程模型,这意味着它的所有操作都是在一个线程内完成的,不需要进行线程切换和上下文切换。这大大提高了 Redis 的运行效率和响应速度。
- 多路复用 I/O 模型:Redis 在单线程的基础上,采用了I/O 多路复用技术,实现了单个线程同时处理多个客户端连接的能力,从而提高了 Redis 的并发性能。
- 高效的数据结构:Redis 提供了多种高效的数据结构,如哈希表、有序集合、列表等,这些数据结构都被实现得非常高效,能够在 O(1) 的时间复杂度内完成数据读写操作,这也是 Redis 能够快速处理数据请求的重要因素之一。
- 多线程的引入:在Redis 6.0中,为了进一步提升IO的性能,引入了多线程的机制。采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
!概述
所说的Redis单线程,指的是”其网络IO和键值对读写是由一个线程完成的”,也就是说,Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。
所以说,Redis中并不是没有多线程模型的,早在Redis 4.0的时候就已经针对部分命令做了多线程化。
一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。
其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O。计算操作主要涉及到CPU。
而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。
之所以Redis没有用多线程处理IO操作,主要是因为,Redis的操作基本都是基于内存的,CPU资源根本就不是Redis的性能瓶颈。
Redis并没有在网络请求模块和数据操作模块中使用多线程模型,主要是基于以下四个原因:
- Redis 操作基于内存,绝大多数操作的性能瓶颈不在 CPU
- 使用单线程模型,可维护性更高,开发,调试和维护的成本更低
- 单线程模型,避免了线程间切换带来的性能开销
- 在单线程中使用多路复用 I/O技术也能提升Redis的I/O利用率
还是要记住:Redis并不是完全单线程的,只是有关键的键值对读写是由一个线程完成的。
!多路复用概述
Linux多路复用技术,就是多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。
通过一个线程来处理多个IO流。
IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但具体细节各有不同。
其实,Redis的IO多路复用程序的所有功能都是通过包装操作系统的IO多路复用函数库来实现的。每个IO多路复用函数库在Redis源码中都有对应的一个单独的文件。
在Redis 中,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
完全基于内存
Redis完全基于内存,大部分都是简单的存取操作,大量的时间花费在 IO 上。Redis 绝大部分操作时间复杂度为 O(1),所以速度十分快。
非阻塞 IO、多路 IO 复用模型
Redis 采用多路 IO 复用模型,在内部采用epoll 代理。多路是指多个网络连接,IO 复用是指复用同一个线程。epoll 会同时监察多个流的 IO 事件,在空闲时,当前线程进入阻塞,如果有 IO 事件时,线程会被唤醒,并且 epoll 会通知线程是哪个流发生了 IO 事件,然后按照顺序处理,减少了网络 IO 的时间消耗,避免了大量的无用操作。
单线程
对于单线程来讲,不存在上下文切换问题,也不用考虑锁的问题,不存在加锁释放锁的操作,没有因为可能出现死锁而导致的性能消耗。虽然单线程无法发挥出多个 CPU 的性能,但是可以在单机开启多个 Redis 实例解决这个问题。reids 的单线程是指处理网络请求只有一个线程。
每次上下文切换都需要花费几十纳秒到数微秒的 CPU 时间,也就是说如果频繁的进行上下文切换会导致 CPU 大部分时间被浪费。
在关系型数据库中,会通过加锁来保证数据的一致性,这种锁被称为悲观锁。Redis 为了近可能的减少客户端等待,使用 WATCH 命令对数据加锁,只会在数据被其他客户端修改时,才会通知执行 WATCH 的客户端,之后的事务不会执行。这种加锁方式被称为乐观锁,极大的提升了 Redis 的性能。
数据结构简单
数据结构设计简单,对数据的操作也简单,Redis 中的数据结构是专门进行设计的。Redis 的数据结构有简单动态字符串、链表、字典、跳跃表、整数集合、压缩字典。
简单动态字符串
Redis 并没有使用 C 语言的字符串,而是使用了简单动态字符串(SDS)。相对于 C 语言的字符串来讲,SDS 记录了自身使用和未使用的长度,时间复杂度为 O(1),而 C 语言则要遍历整个空间,时间复杂度为 O(N)。
SDS 可以通过自身长度来判断字符串是否结束,这样可以实现二进制数据的存储。
链表
Redis 的链表为双端链表,链表节点带有 perv 和 next 指针,链表还带有 head 和 tail 指针,使得获取链表某节点前后置节点的时间复杂度都是 O(1)。并且 Redis 链表无环,prev 和 next 指针指向 null,对链表的访问以 null 作为截至的判断条件。
链表中有记录自身长度的属性 len,并且链表使用 void*指针来保存节点值,可以通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以用来保存各种不同类型的值。
字典
字典由哈希表组成,而哈希表又由哈希结点组成。
跳跃表
跳跃表是一种有序数据结构,通过在每个结点中维持多个指向其它结点的指针,从而达到快速访问结点的目的。Redis 中在有序集合键和集群结点中的内部数据结构都用到了跳跃表。
整数集合
Redis 用于保存整数值的集合抽象数据结构,它可以保存类型为 int16_t、int32_t 或者 int64_t 的整数值,并且保证集合中不会出现重复元素。
压缩列表
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意个结点,每个结点可以保存一个字节数或者一个整数值。
Redis 优秀的过期策略和内存淘汰机制
定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。对内存最友好,对 CPU 时间最不友好。
惰性删除:放任键过期不管,但是每次获取键时,都检査键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。对 CPU 时间最优化,对内存最不友好。
定期删除:每隔一段时间,默认 100ms,程序就对数据库进行一次检査,删除里面的过期键。至 于要删除多少过期键,以及要检査多少个数据库,则由算法决定。前两种策略的折中,对 CPU 时间和内存的友好程度较平衡。
Redis 使用惰性删除和定期删除
内存淘汰机制
Redis 的内存淘汰机制有六种:
volatile-lru:内存不足时,删除设置了过期时间的键空间中最近最少使用的 key
allkeys-lru:内存不足时,在键空间中删除最少使用的 key
volatile-random:内存不足时,随机删除在设置了过期时间的键空间中的 key
allkeys-random:内存不足时,随即删除在键空间中的 key
volatile-ttl:内存不足时,在设置了过期时间的键空间中,优先移除更早过期时间的 key
noeviction:永不过期,返回错误
还有两种 4.0 新增的:基于 LFU.
在以上的淘汰策略中,使用 allkeys-lru 较好。
在 redis 6.0 之前,redis 的核心操作是单线程的
因为 redis 是完全基于内存操作的,通常情况下 CPU 不会是 redis 的瓶颈,redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
既然 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了,因为如果使用多线程的话会更复杂,同时需要引入上下文切换、加锁等等,会带来额外的性能消耗。
而随着近些年互联网的不断发展,大家对于缓存的性能要求也越来越高了,因此 redis 也开始在逐渐往多线程方向发展。
最近的 6.0 版本就对核心流程引入了多线程,主要用于解决 redis 在网络 I/O 上的性能瓶颈。而对于核心的命令
执行阶段,目前还是单线程的。
Redis 的网络事件处理器(Reactor 模式)
redis 基于 reactor 模式开发了自己的网络事件处理器,由 4 个部分组成:套接字、I/O 多路复用程序、文件事件分 派器(dispatcher)、以及事件处理器。
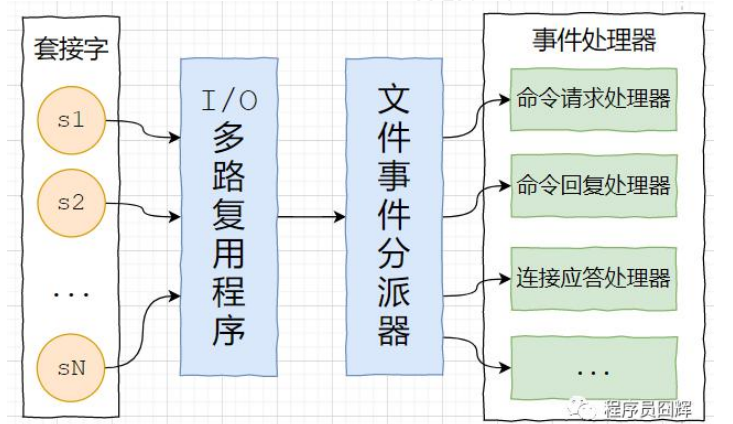
套接字:socket 连接,也就是客户端连接。当一个套接字准备好执行连接、写入、读取、关闭等操作时, 就会产生一个相应的文件事件。因为一个服务器通常会连接多个套接字, 所以多个文件事件有可能会并发地出现。
I/O 多路复用程序:提供 select、epoll、evport、kqueue 的实现,会根据当前系统自动选择最佳的方式。负责监听多个套接字,当套接字产生事件时,会向文件事件分派器传送那些产生了事件的套接字。当多个文件事件并发出现时, I/O 多路复用程序会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件事件分派器传送套接字:当上一个套接字产生的事件被处理完毕之后,才会继续传送下一个套接字。
文件事件分派器:接收 I/O 多路复用程序传来的套接字, 并根据套接字产生的事件的类型, 调用相应的事件处理器。
事件处理器:事件处理器就是一个个函数, 定义了某个事件发生时, 服务器应该执行的动作。例如:建立连接、命令查询、命令写入、连接关闭等等
Redis 事务的实现
一个事务从开始到结束通常会经历以下 3 个阶段:
1)事务开始:multi 命令将执行该命令的客户端从非事务状态切换至事务状态,底层通过 flags 属性标识。
2)命令入队:当客户端处于事务状态时,服务器会根据客户端发来的命令执行不同的操作:
exec、discard、watch、multi 命令会被立即执行
其他命令不会立即执行,而是将命令放入到一个事务队列,然后向客户端返回 QUEUED 回复。
3)事务执行:当一个处于事务状态的客户端向服务器发送 exec 命令时,服务器会遍历事务队列,执行队列中的所有命令,最后将结果全部返回给客户端。
WATCH 命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。
监控一直持续到EXEC 命令(事务中的命令是在 EXEC 之后才执行的,所以在 MULTI 命令后可以修改 WATCH 监控的键值)
不过 redis 的事务并不推荐在实际中使用,如果要使用事务,推荐使用 Lua 脚本,redis 会保证一个 Lua 脚本里的所有命令的原子性。
Lua 脚本
lua 轻量级脚本语言
在数据库中,事务的ACID中原子性指的是”要么都执行要么都回滚”。在并发编程中,原子性指的是”操作不可拆分、不被中断”。
Redis既是一个数据库,又是一个支持并发编程的系统,所以,他的原子性有两种。所以,我们需要明确清楚,在问”Lua脚本保证Redis原子性”的时候,指的到底是哪个原子性。
Lua脚本可以保证原子性,因为Redis会将Lua脚本封装成一个单独的事务,而这个单独的事务会在Redis客户端运行时,由Redis服务器自行处理并完成整个事务,如果在这个进程中有其他客户端请求的时候,Redis将会把它暂存起来,等到 Lua 脚本处理完毕后,才会再把被暂存的请求恢复。
这样就可以保证整个脚本是作为一个整体执行的,中间不会被其他命令插入。但是,如果命令执行过程中命令产生错误,事务是不会回滚的,将会影响后续命令的执行。
也就是说,Redis保证以原子方式执行Lua脚本,但是不保证脚本中所有操作要么都执行或者都回滚。
那就意味着,Redis中Lua脚本的执行,可以保证并发编程中不可拆分、不被中断的这个原子性,但是没有保证数据库ACID中要么都执行要么都回滚的这个原子性。